
这次的实测和解读有视频版本,可以参考B站充电会员专属:
今天分享的内容很简单:

兑现之前双卡A770跑大语言模型升级到3卡,我之前有一张A770,另外两张A770是Intel测评借过来的,理论上之前就可以测试三卡,但是有一个问题,我的主板虽然多,但是抓不到一个可以插入3张显卡的;或者说有一个,但是内存适配后不够大,于是就需要一张全新的主板来结局问题:

之前的分享有解读到可以借助华硕的哎哟喂系列主板来搞定,比如哎哟喂的Z790或Z890可以很好的支持3个或4个显卡插槽,如上我们借到了一张华硕的Z890 AYW GAMING WIFI W(白色)主板。

不过实际操作上和我上次讲的略有不同,三张显卡还是无法全部直接插入ATX主板,需要借助一根显卡延长线来实现,比如上图就可以看到有一张A770其实是外挂的,不过这并不影响我们的测试和实操。

另外一个不同是之前说的外挂电源来解决8pin供电接口不足的问题,实测外挂不行。诡异的发现外挂的显卡亮红灯(蓝戟logo变红色)且系统无法识别这张显卡。
于是我就做了一个更骚的操作:已知一个8pin显卡供电接口是串联的双8pin,供电能力不变,在llama.cpp上并不能完全发挥满载功耗,所以我把3个8pin分别为A1/A2/B1/B2/C1/C2,错开接上去:
第一张显卡接入A1\B2,第二张显卡接入B1\A2,第三张显卡接入C1\C2。
实测整机满载320瓦多一点点,所以完全够用,但是如果基于Linux下的vllm,就不一定够了。
预热的内容就这么多,下面我们来看硬件的组合细节:
文章目录
配件清单
- 主板:华硕Z890 AYW GAMING WIFI W(白色)主板;
- CPU:Intel酷睿Ultra 9 285K盒装;
- 内存:海盗船24GB x2(OC8000)+宏碁16GB x2(OC8000),实际基于OC6000频率;
- 硬盘:宏碁N7000 2TB(不推荐选购);
- 散热器:利民SS135银魂风冷散热器;
- 显卡:蓝戟Photon版A770 Intel独显(两张黑色+1张艾尔登法环联名版);
- 电源:先马1000瓦金牌Plus 80(已停产);
- 至少一根PCIe 4.0 x16的显卡延长线(x16是标配,但是否是PCIe4.0要看清楚了)。
关于主板,哎哟喂属于华硕的其它系列,官网甚至不太好找,简单来说属于两大管饱主打性价比:

所以这玩意接口上就比较抠门了,不仅没有USB4或者雷电4接口,也仅有一个20Gbps版本的USB4接口;但是USB 2.0接口足足给了4个,外带3个10Gbps的USB-A接口,显示输出方面给了一个DP2.1:

好在供电虽然不如吹雪、HERO那么高,但是作为Z890而言肯定是够的。

显卡接口如上,第二个肯定会被挡住,除非多数都用显卡延长线;主显卡为G5模式的PCIE5.0,配备的按压拆显卡工具讲真还比较好用,比按钮方便。固态方面支持4个M.2,均支持x4模式。
关于CPU,优势在于有一个支持AI加速的iGPU核显:
但实际上基本不会用到,所以CPU上没有特别的限制。
关于内存,实际4个插槽插满也可以OC到更高,因为这是800系列主板的优势之一:
但是因为测试时间比较紧张,所以我就没有不断的修改OC频率进行稳定性测试。

目前800系列主板起步就可以支持OC8000,且目前新OC8000内存更便宜,推荐选择。但是需要注意该内存仅限于新的800系列主板才可以用,比如老的Z790、B760主板是不支持的哦。也就说这种福利仅适用于新主板和新CPU的专利(含AMD的800系列平台)。
关于硬盘,这款是一个QLC颗粒,所以不推荐(实际推荐佰维的NV7000,毕竟价格差异不大)。
关于散热器,大路一直推荐利民的SS135:

优势在于小双塔单风扇可以轻易的满足260瓦稳定持续输出,尤其是目前仅200元出头搭配了二次动平衡风扇非常安静,尤其是非满载的条件下安静得令人发指。
关于电源:之前说了,单A770显卡需要双8pin,满载需要独立的两根8pin供电,非满载才可串联。所以满载需要6个8pin显卡供电,可推荐ROG的满配1200瓦电源(含6根8pin供电线,重点哦,这种线不通用)。
llama.cpp
因为支持为了测试效果,肯定选择最简单实操性最强的Intel官方优化版本:
https://www.modelscope.cn/models/ipexllm/llama.cpp-ipex-llm
上面是魔塔社区,不需要借助工具即可访问,另外模型访问也可以走魔塔社区下载,速度快。不过和抱抱脸官网下的模型不同在于魔塔社区的模型没有那么全,可能部分的就没有,所以大路走抱抱脸下的。
实测模型包含以下部分:
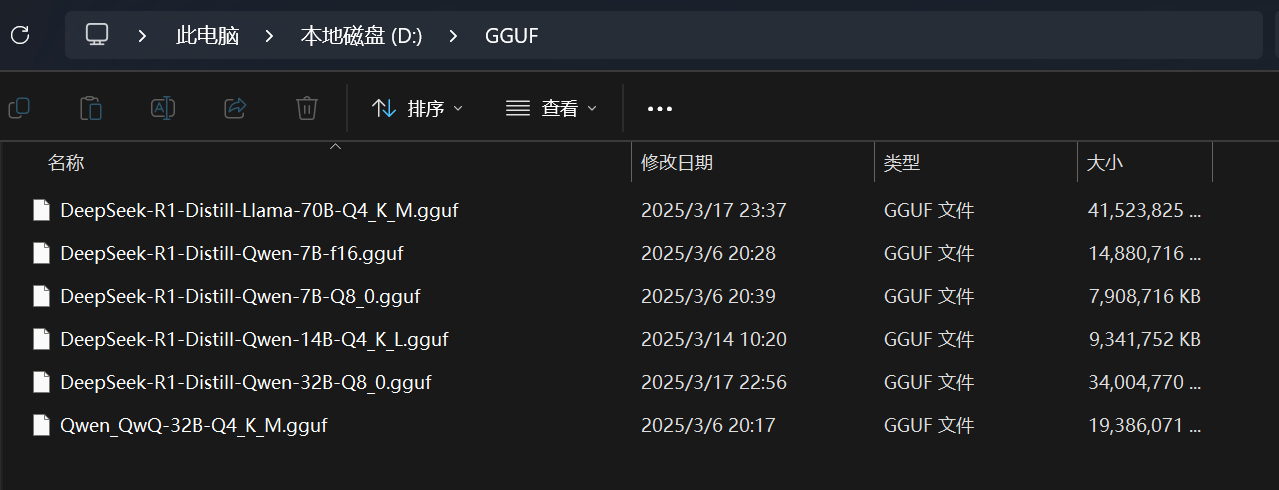
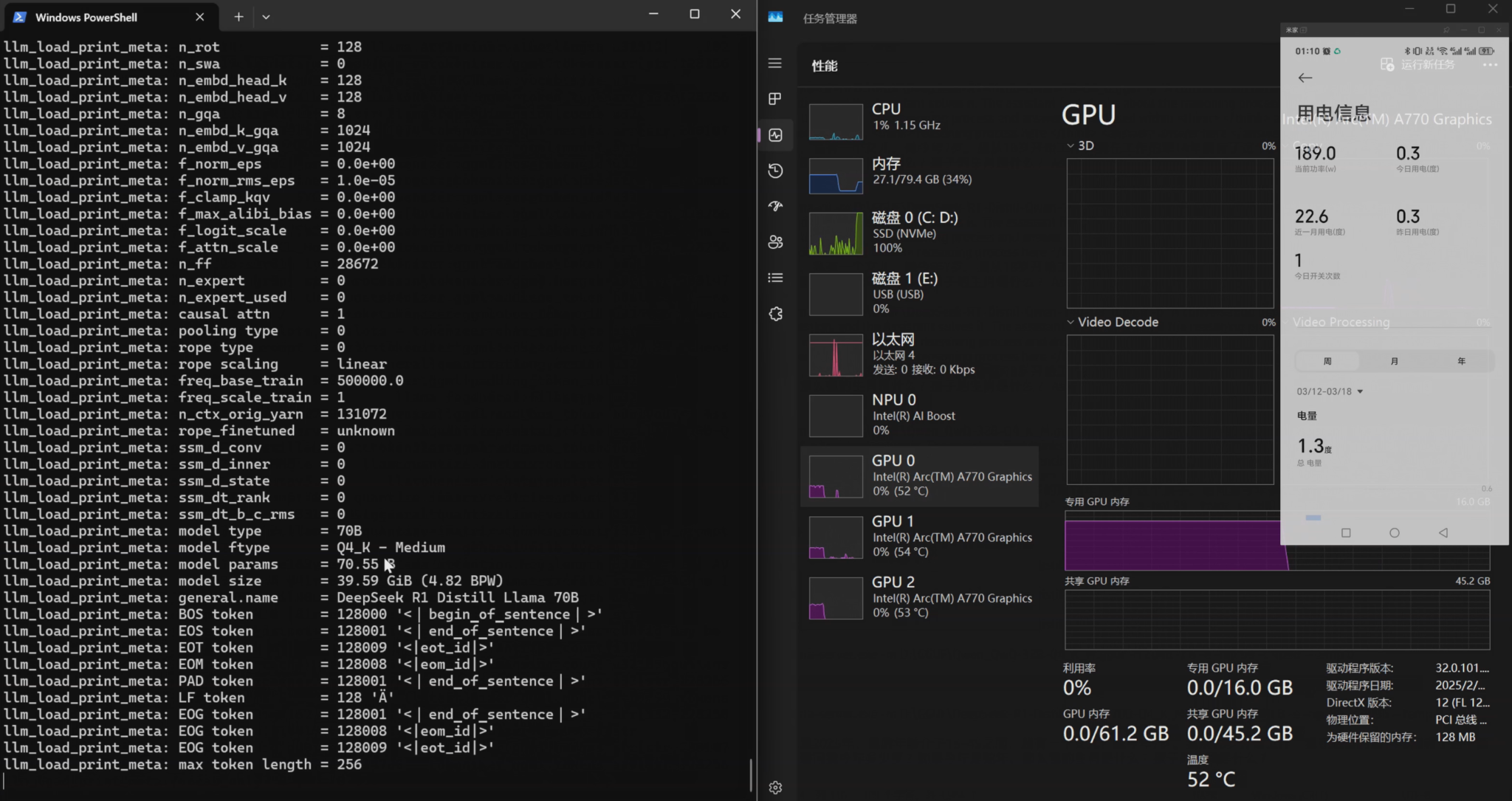
70b只能测试Q4精度的,更高的就超过显卡叠加的显存容量了,基于llama.cpp实测流程中可以发现内存的需求也会很高,所以上面采用了两组不同的内存来组合,否则都测试不了。
实测效果
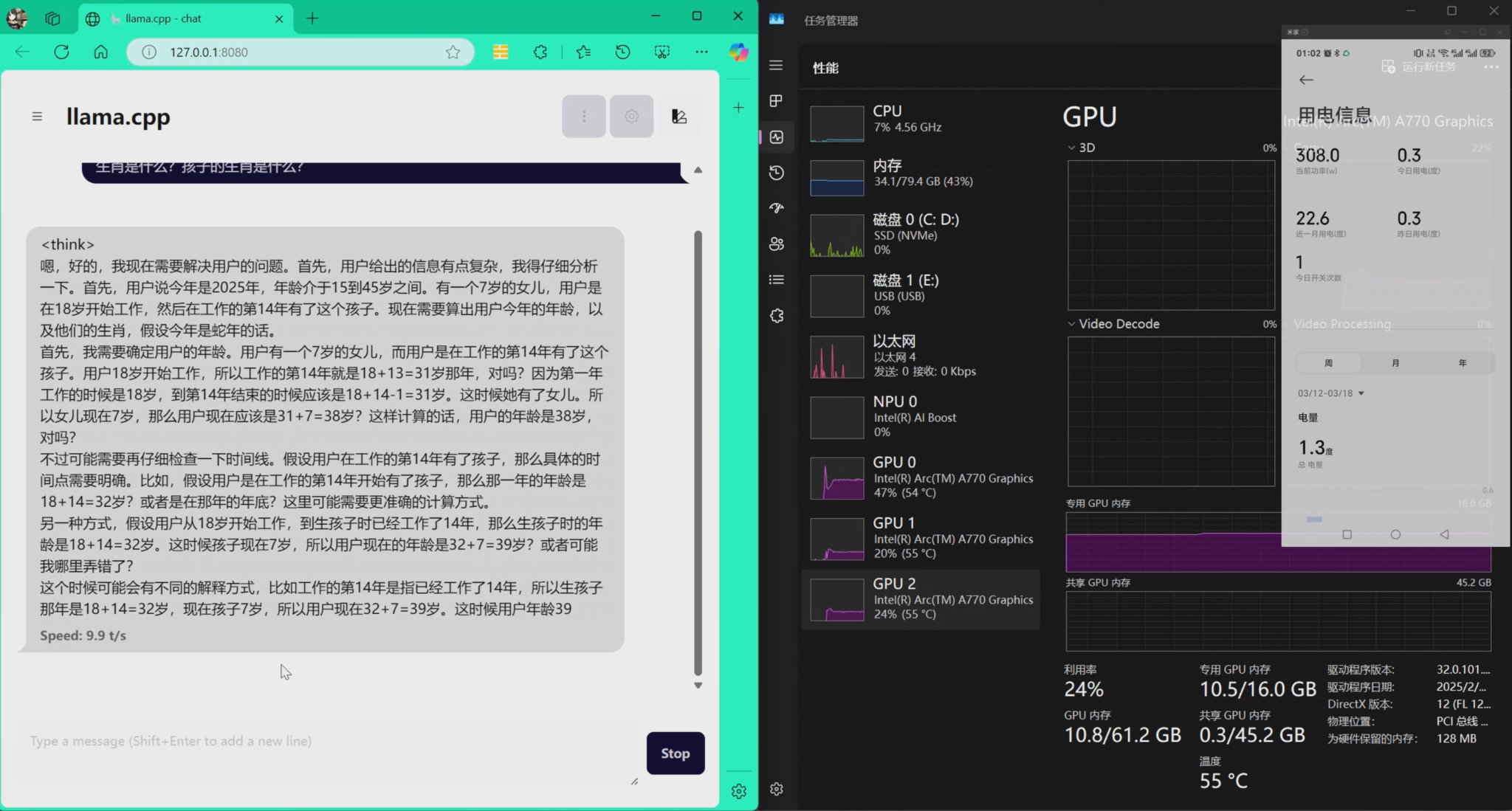
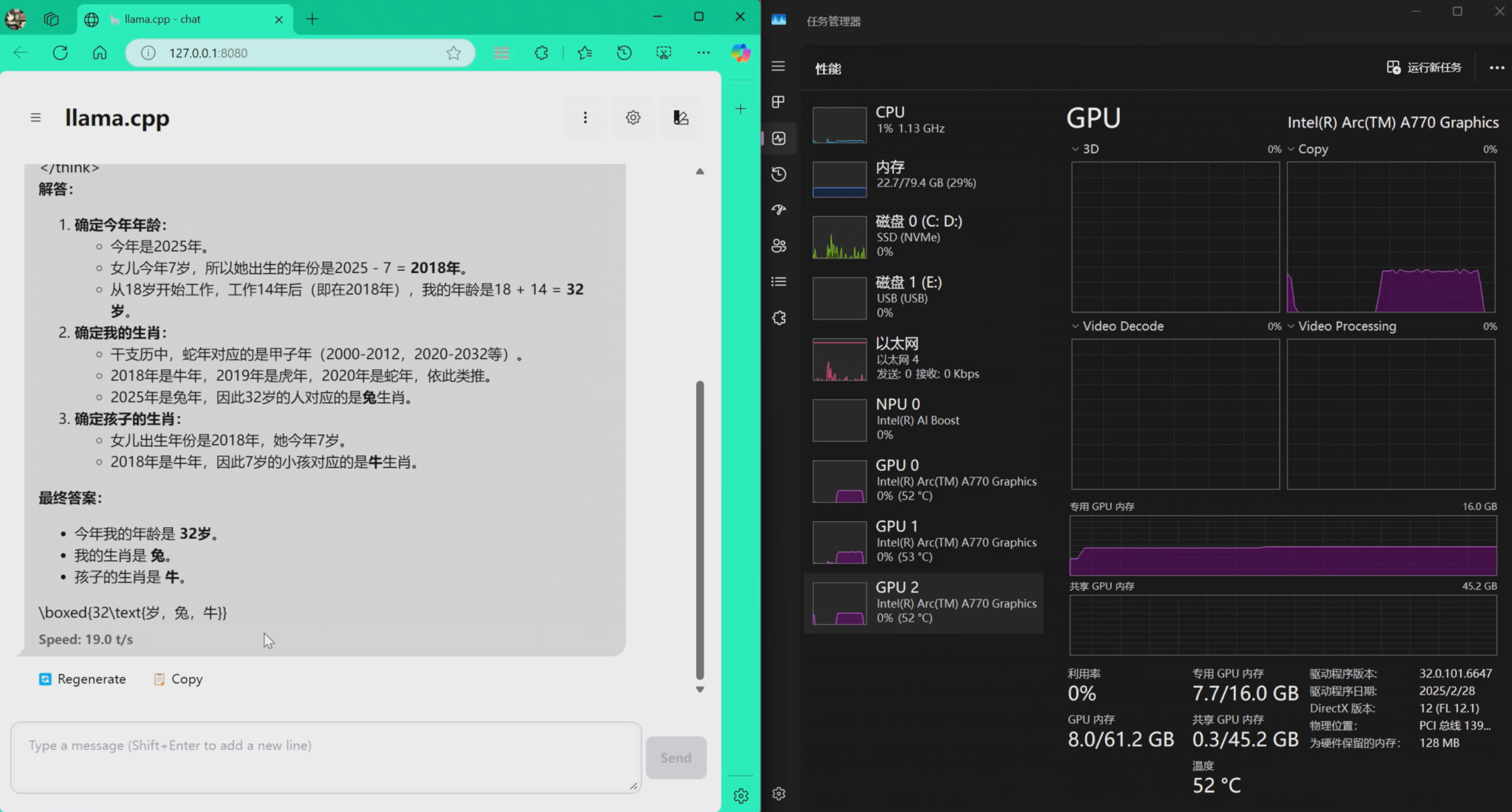
DeepSeek-R1-Distill-Qwen-7B-f16.gguf
速度如下,19tokens/s左右:
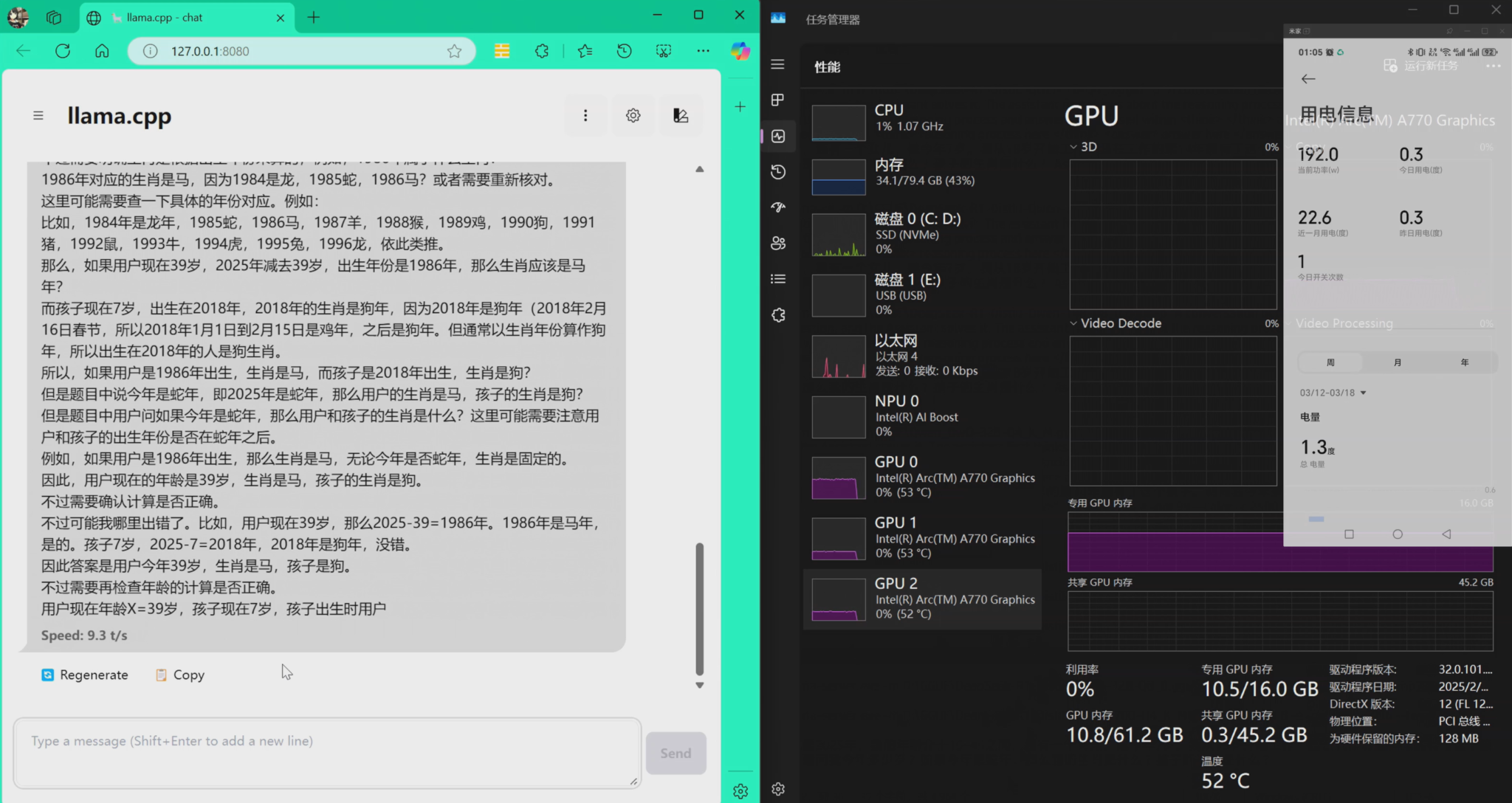
Qwen_QwQ-32B-Q4_K_M.gguf
速度如下,从10多tokens/降低到9.3tokens/s,但是千问的裹脚布太长,用完了tokens也没推出来结果:
DeepSeek-R1-Distill-Qwen-32B-Q8_0.gguf

接下来是Ds的32bQ8,速度差异不大,7.9tokens/s,胜在推完了:
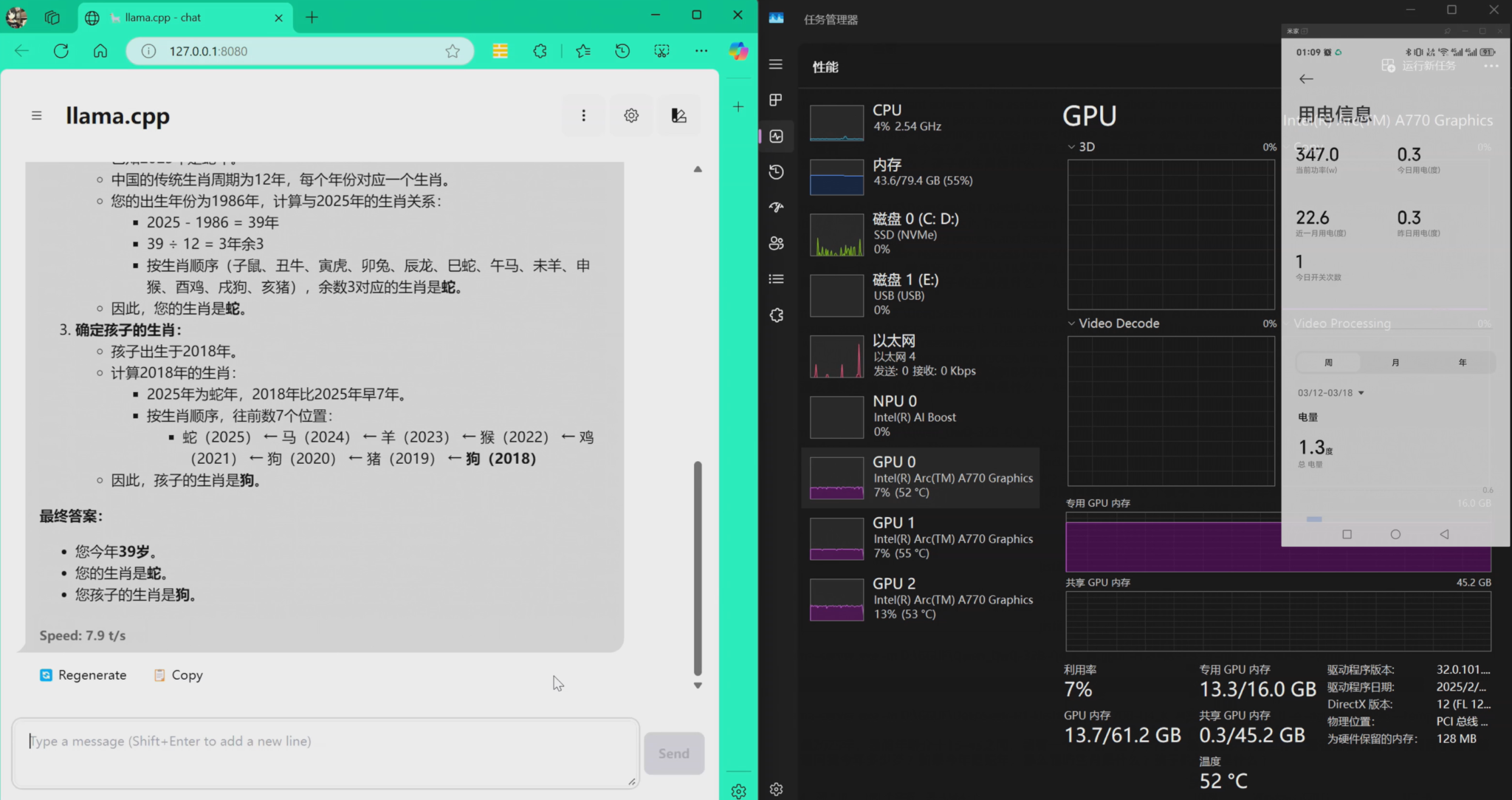
DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf
可以看到速度下降不多,不过功耗的峰值超过了之前说的320瓦,达到了375瓦整机:
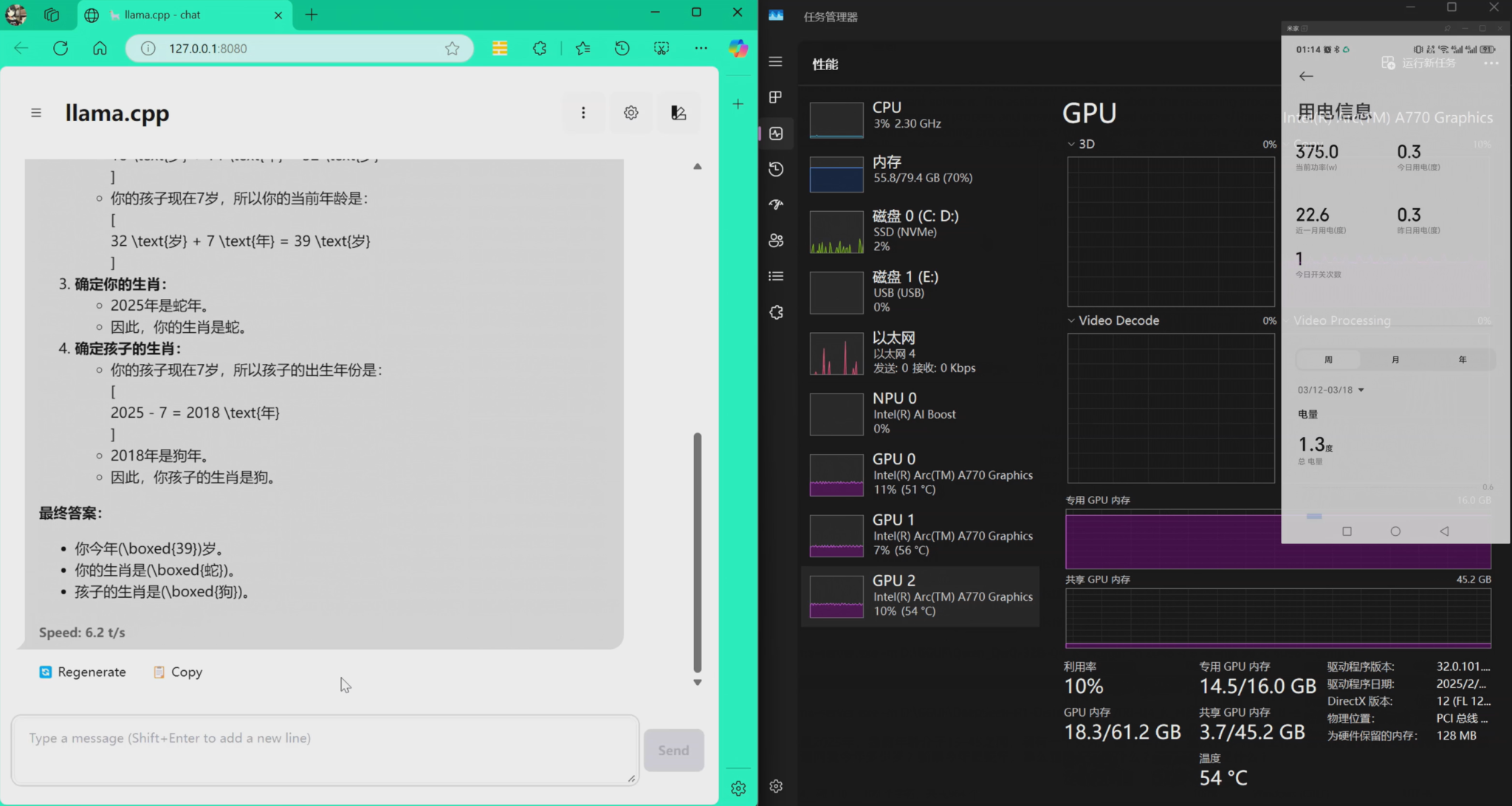
好了,今天的分享就到这里。
Views: 19

