面对这样的话题,相信很多朋友都很困惑,尤其是AI、AI PC像口号一样就这么喊起来了,但是大家感觉落地的貌似又不多,不多的同时微软直接配合硬件厂商、ODM厂商先给你键盘平替一个“AI Copilot”:

这时候尤其是国区用户,吐槽这玩意没啥用,因为Copilot目前没有对国区开放:

虽然你可以通过各种修改最终还要切换到海外IP才能正常使用,最后一看如果要解锁Office套件等功能居然需要订阅,而且就下面这个价格是以月来计算的哦,也就是一年是2000多块钱:
究其原因很简单,这样的AI是云端算力,你需要为云计算的成本付费,因为微软设想是这样的:

随便一台电脑,管你支不支持AI引擎加速,一键打开它的Copilot就是AI PC了。然后钞票就源源不断往微软那边输送了,想得真是太美好了,我做梦都不敢这么做。
然后大家其实也就发现了使用AI方面的内容是要加钱的,有云端的;也有侧端(本地端)结合本地的算力和开源等套件,实现相对固定成本开支的AI硬件之旅,属于相对的成本可控。如果AI最终都源源不断的只存在云端应用接入,那么这个就相当于垄断,反而成为AI发展的壁垒,这是大家不想看到的。
那么我们要本地部署一套AI战略工具,到底会用到CPU还是NPU还是GPU呢?
这不就是今天的主题吗?
文章目录
谁才是AI PC的主角?
要展开今天的话题,我觉得有义务简单普及和科普下,这里面包含了CPU、NPU、GPU。
GPU其实还包含了iGPU和dGPU,iGPU就是集显,dGPU就是独显,众所周知独显肯定AI算力更强。
但是并不代表iGPU就不能用,而且既然都有了dGPU和iGPU,为什么要推出NPU这么一个东西呢?
为了很好的解决这个问题,梳理这个问题,让大家了解CPU、NPU、GPU分别在AI里面扮演什么角色,大路哥花了18小时以上分别做了相对应的基准测试,通过数据分析的方式帮助大家来理解这个话题。
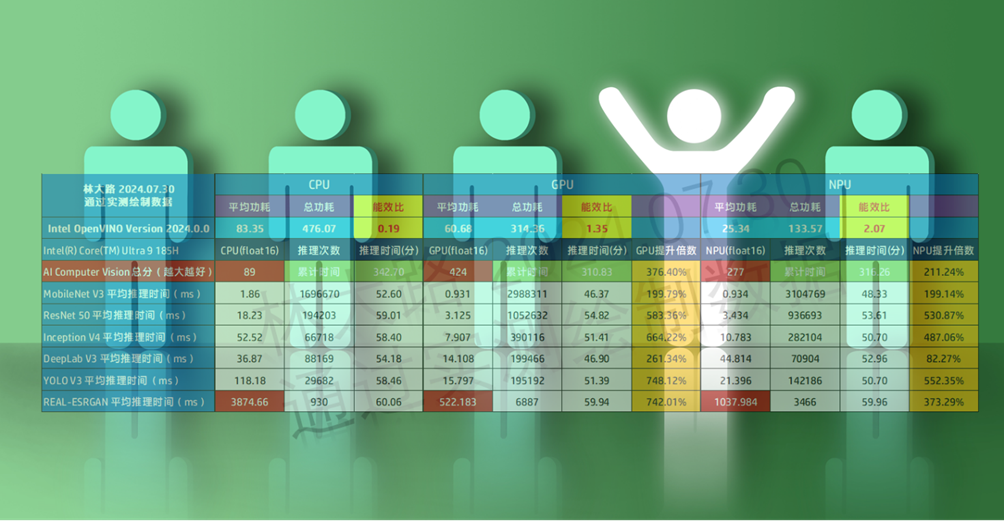
首先我给大家看一个表格,这是我花了18小时才得到的结果:

友情提醒两点:
第一,这篇回答的内容很长,约1万字,看起来有点吓人,实际内容并不枯燥,也就没啥了。
其次内容上也有诸多你听都没听过的术语,用的也是专业收费的工具和流程,但是这个不是难点,因为很简单:这些只是让数据更精确有用、客观,本质是我们对CPU、NPU、GPU做对比,竞技,通过结果来剖析到底谁是主角,以及它们的定位,这也是大家想要的,所以看起来其实很轻松的。
本质上你只需要知道结果,这个结果是公正、客观的,就OK了,顺带了解AI有哪些算法、模型。
先说背景
目前比较公正且支持的比较全面的AI基准工具就是由UL公司提供的Procyon(它不是免费的)工具:
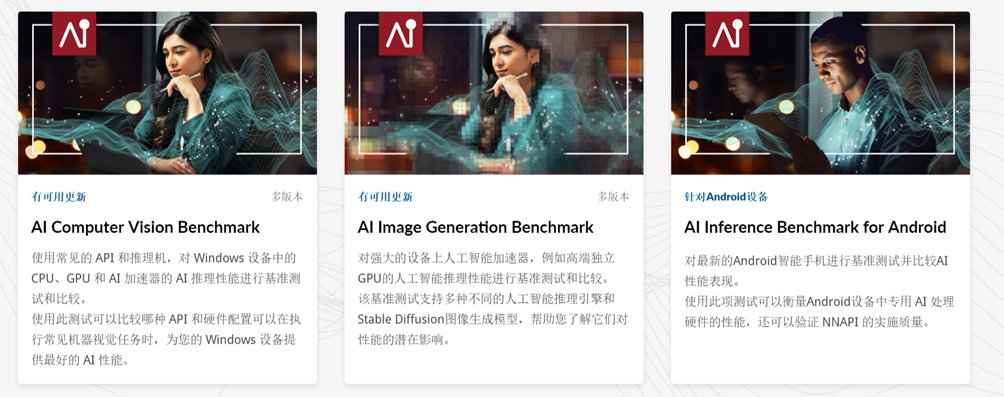
如上包含了3种场景下的基准测试:
- AI Computer Vision Benchmark,可以相对更好的适配所有平台和基准;
- AI Image Generation Benchmark,利用几种不同的Stable Diffusion图像生成模型进行基准测试;
- 这个会限制CPU参与,所以这里没法选择该场景进行测试。
- AI Inference Benchmark for Android,基于安卓的网络神经算法进行基准测试。
所以这里我们会用到AI Computer Vision Benchmark基准测试,它包含了多个赛道:
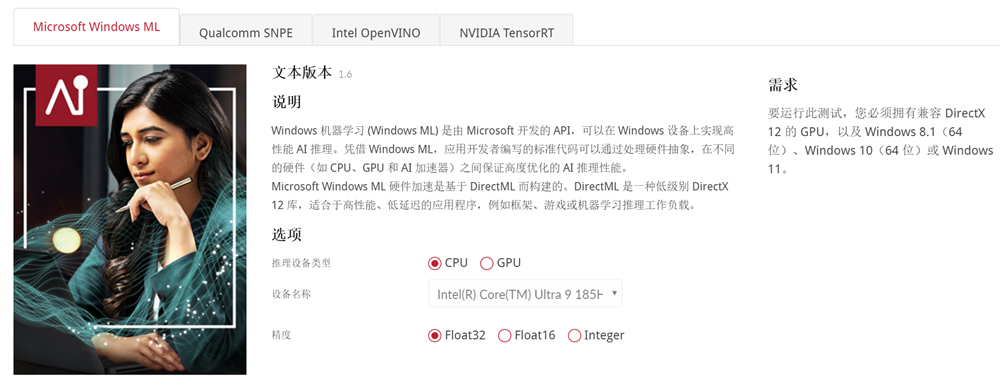
由于微软的ML基准中不包含NPU的测试,所以我们忽略这一个赛道;而Qualcomm SNPE是基于高通平台的,目前还不是主流,所以我们继续忽略这一个赛道;最后的NVIDIA TensorRT仅仅是针对英伟达显卡的,并不能体现CPU和NPU,所以这里也被pass掉了,而真正解决问题的是Intel的OpenVINO:
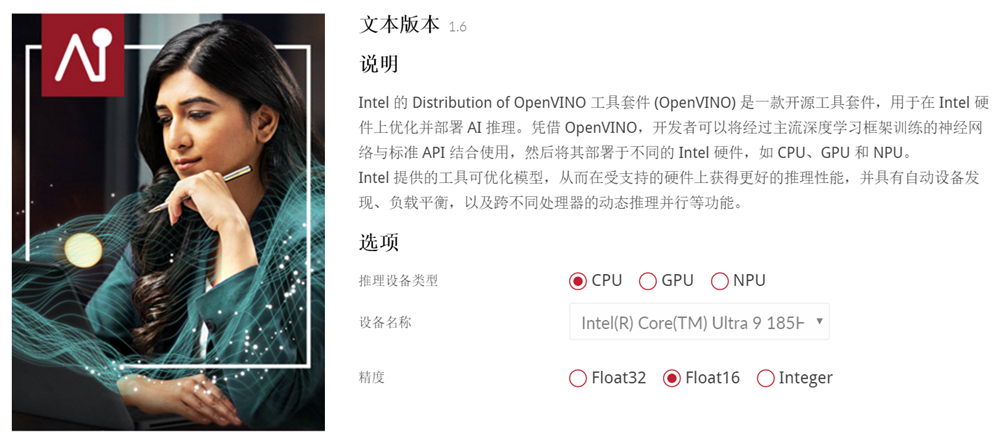
可以看到,它满足了CPU、GPU、NPU下Float32或16等精度测试,可以说很好的展现了我们今天要了解的CPU、NPU和GPU在AI中的位置,负责的角色问题。所以为了体现这一点,我们就需要一套比较合适的硬件平台来展现AI真正的实力和表现,为了更好的表现大路哥这里用到了华硕接手后的NUC 14代:

它的SKU完整名称叫“华硕NUC 14 PRO+”,但内核并非14代Intel处理器,而是最新的酷睿Ultra 这样的真正的AI 处理器,支持CPU、NUP、GPU三引擎加速。之所以选择这款NUC作为代表是因为作为迷你PC的一员,华硕的这款NUC性能释放可以说是迷你PC中的天花板,峰值可达115瓦,持续烤机也可以达到80~90瓦的水平,这个水平完全碾压一种迷你PC不说,自然是碾压轻薄本的。
所以获得的数据可以更好形成对比,通过尽力的释放CPU、NPU的潜力,看是否能和iGPU一战。
其实华硕接手后的这款NUC凭啥可以获得115瓦的峰值释放相信大家也比较好奇,不过这不是今天主要讲的内容,如果大家好奇可以参考我之前写的测评,因为它采用了更好玩的单风扇散热设计:
平台配置
NUC也有不同的配置,华硕的这款包含了酷睿Ultra 5/7/9三个,内存自由搭配,支持DDR5,最高可选择DDR5-5600内存,效果会比4800有更大的优势,成本上差异不大,细节可以参考:
固态硬盘大路哥这里用到是2TB的威刚ADATA SX8200PNP (PCI-E 3.0 x4),读写方面均在3GB/s左右,其实我更倾向于使用这款固态是因为我是用来工作的,SX8200PNP最大的优势就是高速读写中温控非常不错,不管是迷你PC还是更加轻薄狭小空间的笔记本中,都会更加稳定,稳定才是一切:
关于Procyon的AI Computer Vision Benchmark
前面虽然提了一嘴,但只是说了原因,没讲为什么大路哥会花18个小时来完成测试。
首先基于Intel OpenVINO的测试包含了6个项目,分别是:
- MobileNet V3
- ResNet 50
- Inception V4
- DeepLab V3
- YOLO V3
- REAL-ESRGAN
这里的每一项测试都要跑1小时左右,所以完整的跑完大概需要6小时:
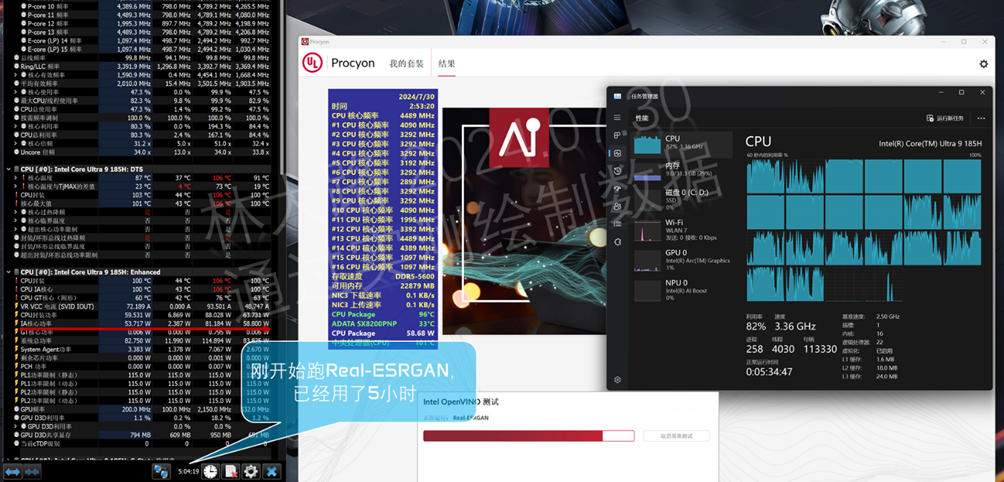
可以负责的说,跑UL的AI基准测试,不亚于一次强度很大的烤机,CPU的AI测试中除了LP核心没有工作,P核E核均介入了进去。而且这个测试最让人头疼的就是不管你算力多强每一项都要跑一个小时左右,它的设计不是你牛逼5分钟跑完就可以进入下一项了,还是得继续跑够1小时,以此获得另外一项数据:推理次数。推理次数越多自然也说明它每一次的推理时间都更短,最后获得的平均数更加准确。
所以单次测试高达6小时的意义就是数据更准确,平均时间更没有误差。
那么上述6个项目具体跑什么呢?
大路觉得展开讲一讲大家也可以更好的了解AI的运行机制、工作原理,这种算法有什么作用?
通过这些更好的了解AI,也可以更好的了解CPU、NUP、GPU在AI中的定位和角色。
MobileNet V3
MobileNet V3顾名思义就是第三代MobileNet算法,这里的Net就是网络,和AI结合就是神经网络,不过Mobile的定义注定了它的设计是属于轻量化网络,定位是边缘设备,AI算力并不是特别强的设备上使用的。所以它的特点是参数少、计算量小、推理时间短,专门处理简单又繁复的工作,比如OCR提取。
OCR用得最多的就是抠字幕,抠PDF或者图片中的文字内容,这也是很普遍的AI任务之一。
但是如果我们参考一些论文、文献就知道它的作用其实满足更多场景,比如:
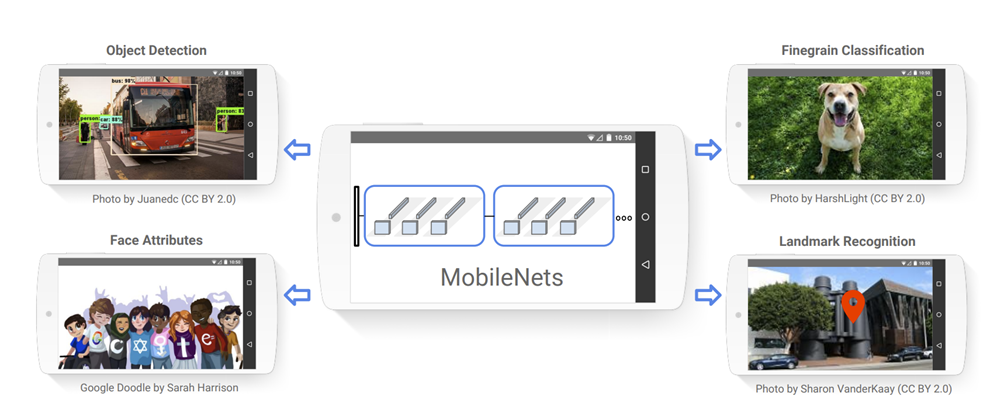
简单来说就是找重点,识别一个图中的重要元素,不限于人的各种物体,配合参数来分类,俗称找不同。
以上配图参考论文:https://arxiv.org/abs/1704.04861
你了解这个以后,你就会明白我们手机中的图片识别,大概率就是基于MobileNet算法来实现的,再配合图片的GIS信息、拍摄时间等信息,联动成更多的分类和场景,让我们感觉很智能化。
ResNet 50
ResNet50其实和上面的MobileNet一样都是基于计算机视觉的算法,结合Res这个名称属性它的定位就是用来分类,识别不同的物体:

大家可以觉得上面的图过于马赛克了,但是你想如果计算机加载一个高清的大图来识别,首先挂巨量的内存开销,算力也跟不上,这些成本都是大家无法接受的。但是即便上面是马赛克一般也能大致的分辨具体是什么物体,实在认不出来就针对这个部分向上高清一点来实现,毕竟计算机只要给一个逻辑和递归的指令,它就不厌其烦的去执行就完事了,但是通过这样的算法可以减少计算机的开销和成本,同时可以获得更快的速度提升,这就是算法的魅力,所以我们才把这些称之为AI进化,这也是为什么这两年AI发展如此之快的原因:
- 先不管准确性,只管速度,就问你快不快吧?
- 然后不断的加参数,反正参数开销没啥成本,提升准确性
- 先解决能用,再说好用
然后你也会发现,不管是跑MobileNet还是ResNet,如果用CPU来跑都是满载的:
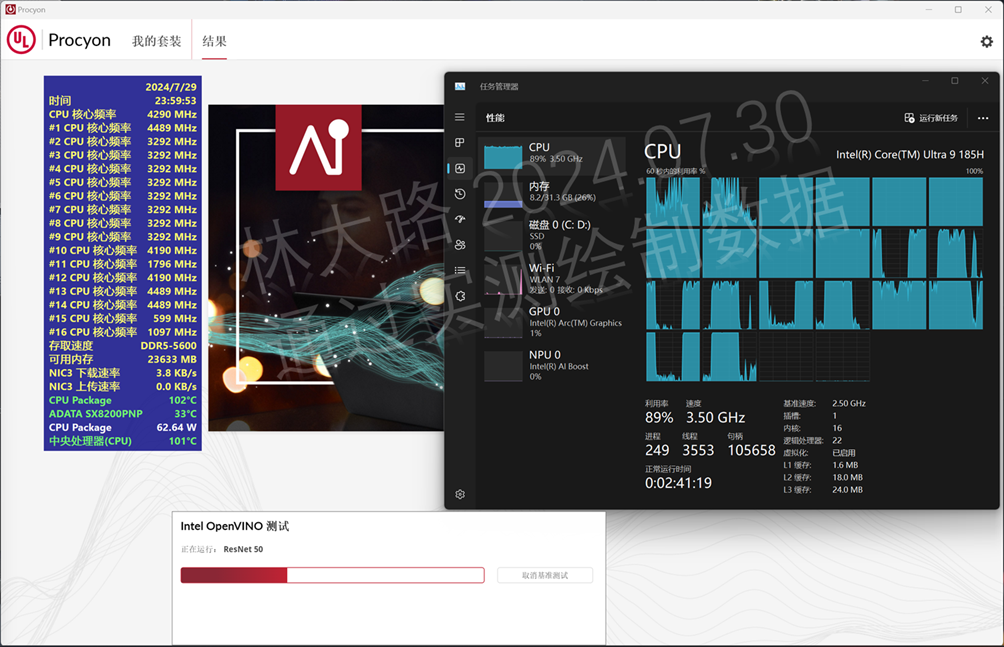
如果我们换成GPU或者专门为AI加速准备的NPU,结果会是如何呢?
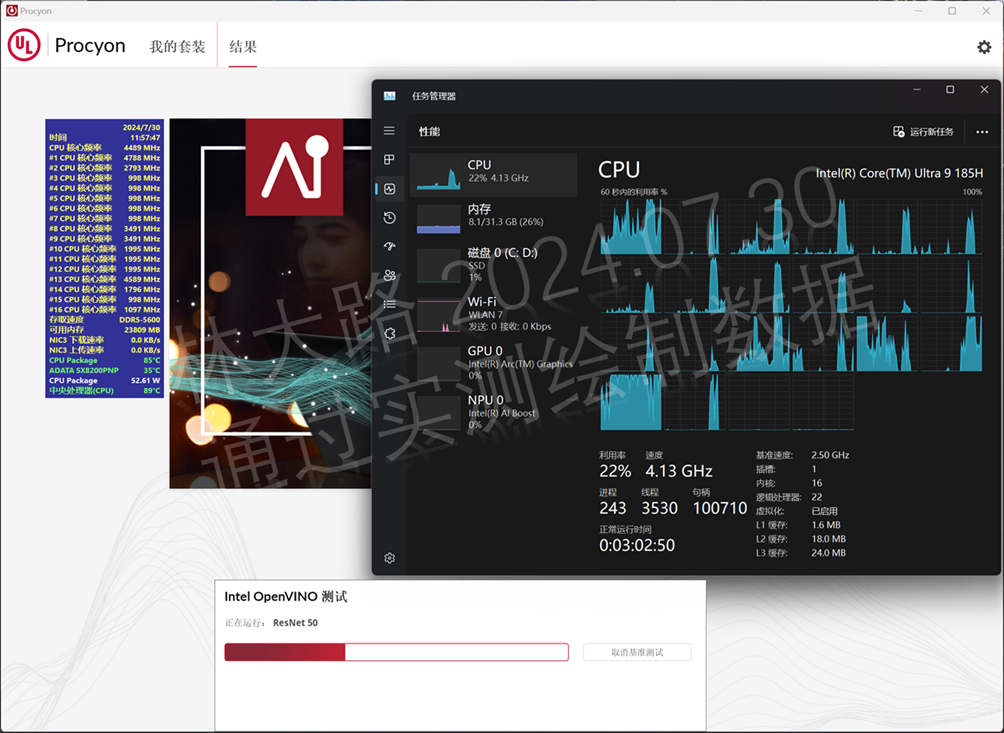
比如上图我们切换到GPU来参与,可以发现ResNet 50还是主要基于CPU来实现,GPU的负载是0%,但是有一个很大的区别,你会发现CPU虽然在工作,但是负载明显变小了。
如果我们切换到NPU来跑呢?
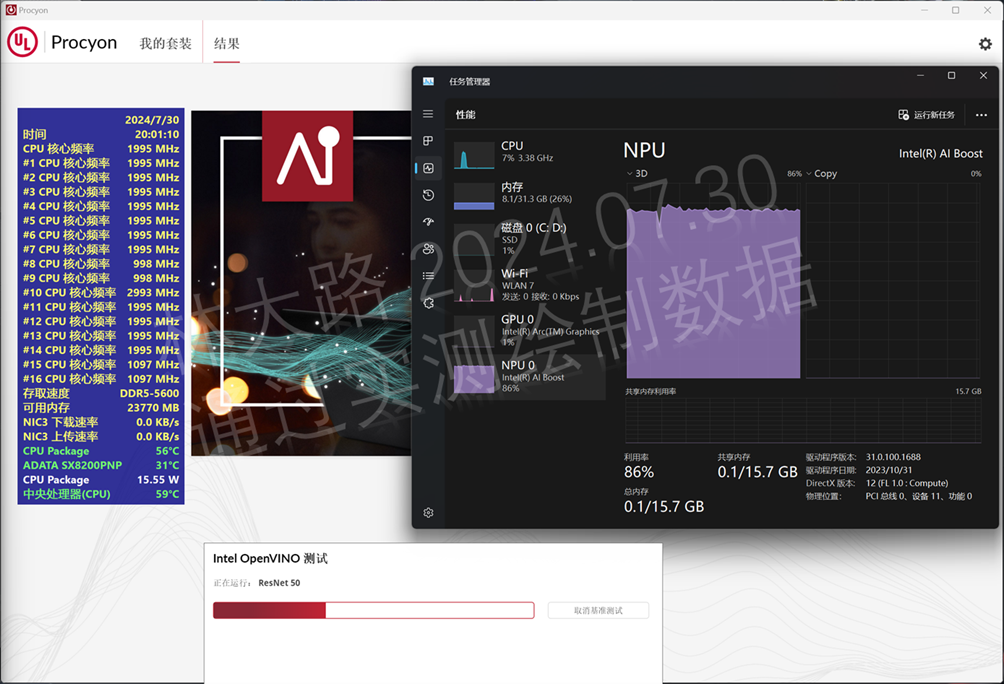
你会发现真正的表演才正式开始,可以看到上图中ResNet 50的测试中NPU几乎是满载,而CPU的介入就非常小了,由于这是一颗酷睿Ultra的处理器,不管是CPU还是NPU还是iGPU的功耗都是可以体现在CPU Package上的,明显的功耗变小了,仅有15瓦左右,和前面的动不动60瓦、50瓦差异就大了。
而且我们只看结果的话如下:

可以看到CPU的每一次推理是18.23ms(毫秒),而这时候的GPU和NPU都在3ms左右,NPU虽然比GPU慢一点点,但是这个差异不大,可以说没有太大的感知,但是整体的功耗开销就小太多了。

注意,上图中的平均功耗是华硕NUC的整机平均功耗,所以NPU的能效比在AI方面更高。同样6个小时的时间限定下NPU只用了133瓦就做了CPU 476瓦才能做的事,或者说GPU 314瓦做的事。
而且从结果来看,NPU的速度并不慢,所以NPU的价值就大大的体现了出来。
但是重点在于你使用的AI平台支持NPU,或者说支持Intel OpenVINO加速的NPU调度。
比如剪映就支持Intel酷睿Ultra的NPU加速,抠图、抠视频背景都可以基于NPU加速。既然剪映能做,其它的应用软件自然也是可以做的,这也是Intel和诸多合作伙伴做的事情,这才是普惠用户嘛。
所以随着AI PC的推进和时间的后移,大家也会逐步在生活中、工作中用到落地的AI级生态应用。
不说生产力、创作力提高多少,光节能减排这一项就已经是举世无双了。
因为这个数据是很直观的,相当于原来5毛钱一公里,现在不到1毛一公里,那就是震撼。

从这一点也说明为什么现在的CPU要做AI CPU,要内置大语言模型,内置AI加速引擎:

可以看到Intel不仅仅支持自己的OpenVINO,也支持第三方的WindowsML和ONNX RT框架加速。不仅Intel在做,同样的AMD也有类似的推进,只是AMD没有那么细化:

所以Intel也有更多基于OpenVINO的平台支持,比如我们常用的绘世这款GUI工具:
它就可以专门的调度能支持AI的Arc 集显或独显,并且可以获得不错的生成速度和效果:
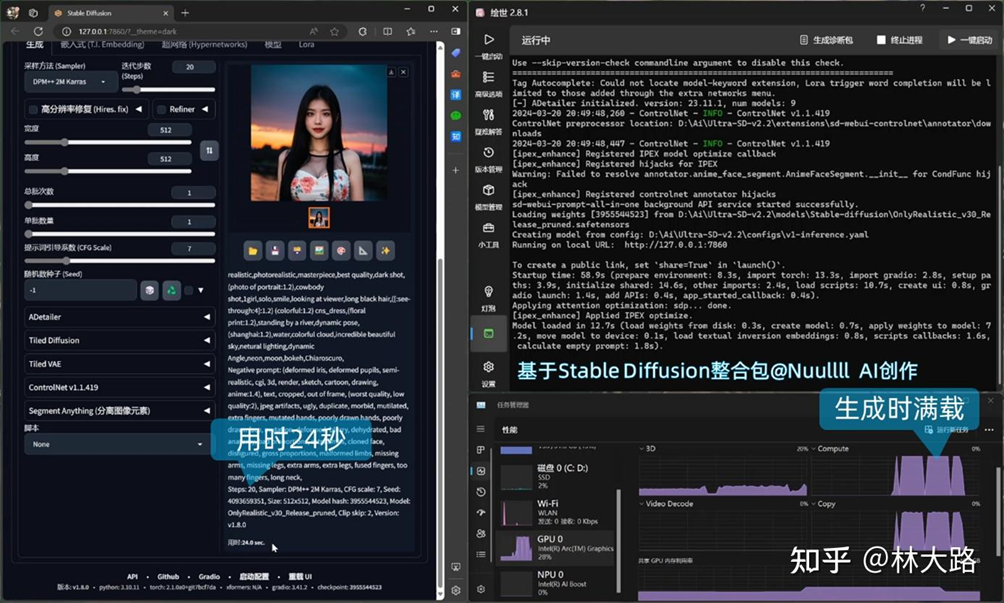
上图为20步迭代的512 x 512效果,如果我们在高清提升下效果,就是这样的:

显然有了AI加速的CPU也可以实现原来独显才能做的事情,简单来说就是把门槛降低了。
Inception V4
Inception V4也是经典的神经网络算法之一,迭代到4代,它还包含了Inception-ResNet。
优势在于提升速率和准确性,V4版本还结合了微软的ResNet,大模型走在最后都是兼容并包。
但是归根结底,Inception v4还是属于分类、计算机视觉的一部分。
我们直接看重点,看看CPU、NPU、GPU之间的差异:

可以看到效率方面GPU还是完胜,而NPU属于猛追,虽然有差距但同样差距不算明显。

如果仅仅使用CPU来跑,同样哼哧哼哧的把自己感动到100℃,用了最大的力,获得了最低的效率。
而GPU的介入就不同了,虽然主要看起来还是CPU在干活,实际在上图的GT核心功率中可以看到iGPU是在主要介入方,只是右边的任务管理器中包含的工作内容无法体现而已。两两结合后的CPU输出是40瓦左右,这样的功率自然CPU的温度就没有那么高了,整机压力也小了,意味着我们在跑AI的同时,我们的计算机还可以做别的事情(但这时候iGPU其实是满载的,可以参考GT核心功率的最大值参考)。但是我们打开网页,写个Word完全毫无压力。
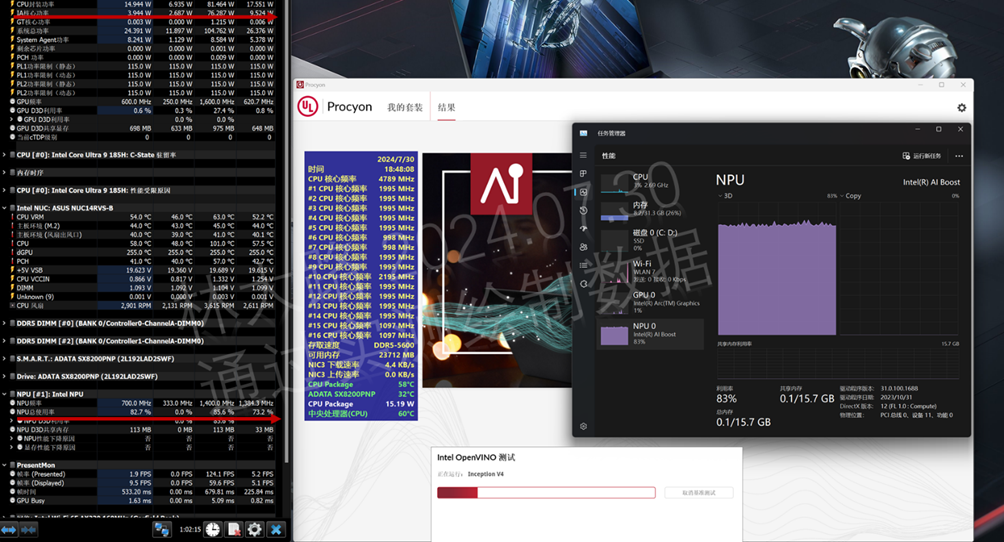
而这时候NPU的介入就完全不同了,如上我们可以看到酷睿Ultra 9 185H的NPU最大频率为1.4GHz(1400MHz),平均值接近满载(1384.3MHz),而CPU的实时功耗IA核心频率为3.944瓦,属于基本上没怎么干活,操作系统的日常消耗水平,这时候我们的CPU温度仅仅为60℃,风扇也没有咆哮,对于涡轮风扇来说仅为2900转,说白了你是感受不到这个NUC在工作的,这时候你即便开个游戏都没有问题。
因为如上可以看到GT核心功率仅为0.003瓦,最大也不过1.215瓦,所以我说玩游戏都没问题,跑AI继续后台跑AI就可以了,这时候NPU的统战价值就完全体现出来了,它并不是没用,也一点都不多余。
并且速度一点都不差。
为了更细节的知道GPU只有在针对GPU的基准测试中是工作的,可以参考监控的数据图表:
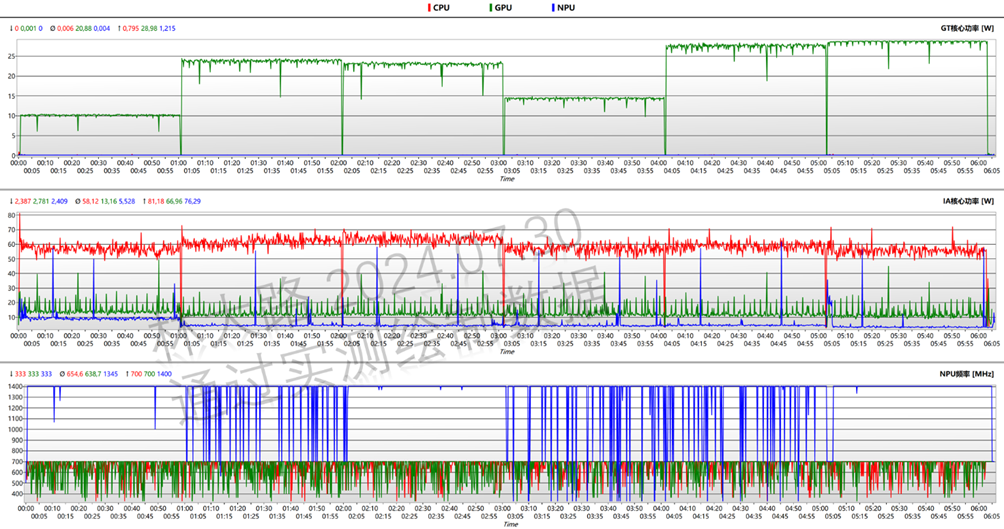
可以看到GPU只有在绿色中有功耗输出,其它两项基于CPU和NPU的测试是几乎“零功耗”的,而IA核心功率代表了CPU的输出,也只有红色(基于CPU的测试)有均值60瓦的输出,其它两项的输出都很低,尤其是NPU方面除前期的MobileNet v3测试中有相对高的输出(10瓦),后期都在5瓦以内。
而NPU方面(蓝色)也只有在NPU基准测试中暴涨到峰值1400MHz,其它两项测试几乎不介入。
DeepLab V3
DeepLab V3属于更进一步的模型处理,如其名Deep,比如官网的介绍是这样的:

相当于它直接屏蔽(而不是忽略)不需要的内容,把需要的更强烈的体现出来。
再退一步讲,它更多的可以针对视频内容逐帧分析:

但是比较意外的是DeepLab v3中对于集显的需求反而下降了,它搭配了CPU和iGPU并行处理:
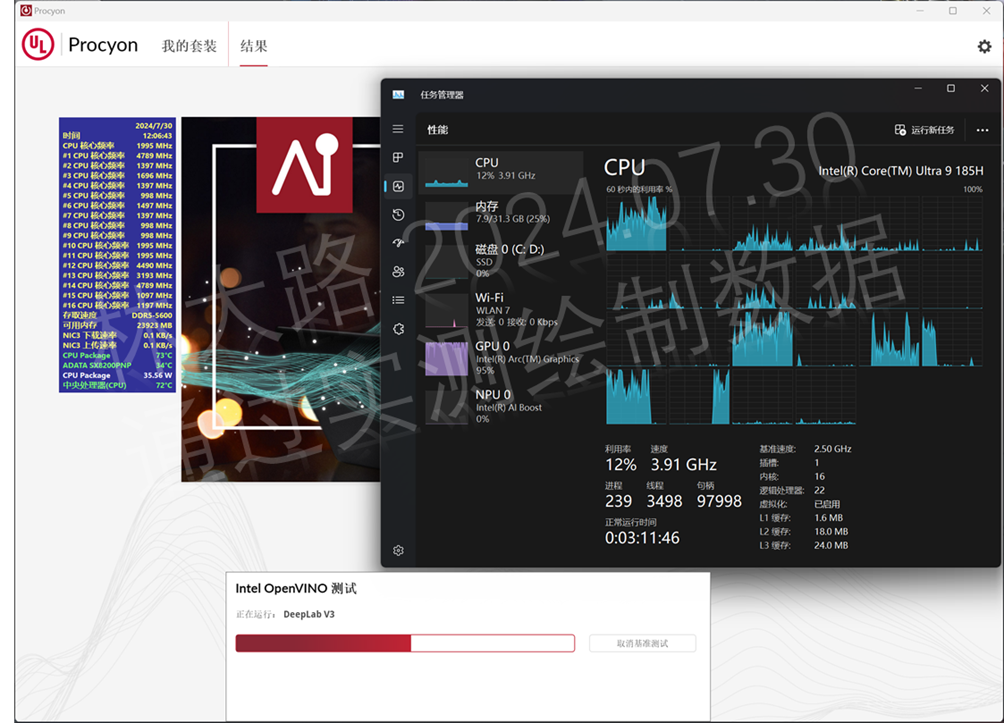
如上可以看到iGPU集显几乎满载的场景下,还调度了多个核心的CPU,不过总体的功耗输出不大。而且和其它算法有所不同,它在使用GPU基准测试中GPU的负载反而更低(参考红圈出来的时间段):
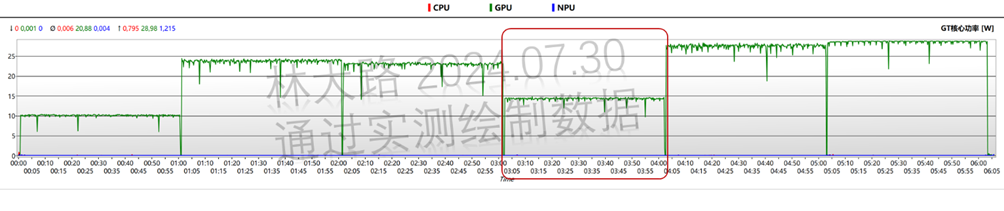
但是不排除Intel OpenVINO框架对于DeepLab的优化更好,所以反而提升了能效比。
YOLO V3
YOLO 是 You Only Look Once 的缩写。它同样是一种使用深度卷积神经网络学得的特征来检测对象的目标检测器,当然我们也称之为一种算法,用来分类,用来计算机视觉识别。

本质的逻辑还是不断的推进和演化,又快有准的识别物体,它的速度相对折中一些:

同样也是iGPU速度最快,NPU次之,NPU的速度也在接受范围内。
真正的区别在于下面的REAL-ESRGAN算法,因为它的作用和上述的算法都不同。
REAL-ESRGAN
它的作用顾名思义就是对图像清晰化,可以叫做超采样,或者“图像超分辨率”:

通过降噪、对比度、脑补画面修复等等一系列的操作,讲原图更加的清晰化、具象化。
所以毫无疑问,真正的GPU在这里会获得无与伦比的加成:

在同样的酷睿Ultra 9 185H中相比NPU直接获得了翻倍的速度,而这时候CPU是最难的了,可以说几乎啃不动这个任务了,这个任务也是iGPU和dGPU独显的差异之一。
因为图像的超分辨率不仅仅是提升清晰度,而是把小图放大数倍,2倍、4倍后再清晰化,对于一些老照片、老电影都可以应用到这样的场景中,尤其是老电影这种商业化的价值更大。
大家都知道《星战》系列,每一部跨度的时间比较长,第一部和第七部都差了几十年,摄像机的技术也获得了飞跃的发展,你拿第七部的画质和第一部的相比,那简直没法比:

而作为大厂,必然要对前面的作品进行高清修复,在以前的技术就很难了,所以如上的总结,部分内容是重新拍的,本来《星战》这样的科幻巨制成本就很高,不管是重新拍还是借助CG成本都非常高。
而有了超分辨率技术,这种问题就可以很好的解决了:
我们知道一般电影都是23~24帧之间,相当于1秒钟的画面由24张图片构成,类似于TOPAZ这样的视频高清修复工具就是这样做的,一部电影由数万帧组成,也就有数万张照片,每一张照片逐步高清修复,在合成在一起,还原为原来的23.976帧,这时候你再看,画面就清晰太多了。
超分辨率的同时,还去除了以往老电影的一些噪点,有了AI的普及,这种事情不仅电影公司可以做,个人玩家、影迷也可以把以往的老电影进行修复,尤其是动画片这种线条加配色获得的效果更高。
比如这样:

这是我之前写的一篇文章,为了写这篇文章我也真正的去做了一遍,原来的《萧十一郎》是480p的:
你可能不了解480p和4K的差距,为了体现这一点参考上图就明白了,480p占据的画面只是4K种的一小块,真正的一小块,如果直接放大到4K的画面,那就是肉眼可见的模糊了,而100%下画面其实很清晰。但是当下我们没办法接受这种分辨率的视频投放到4K电视上播放,所以需要高清修复。

如上对比风四娘的头发,左一是模糊的,而越往后提升画质和分辨率,头发丝开始清晰起来。
当然这样的高清修复比较花时间,我只截取了片段进行测试,推算这样的电影借助Intel A750独显来做,需要花大概19个小时多一些,看起来很长,实际也能接受。毕竟原来只有机构、电影公司能做的事情,现在一张1500元的独显就可以完成了,这种对比是十分震撼的。
另外上面我之所以用Intel的独显来做,是因为Intel在这方面其实具备更多的优势,而且Topaz本身也和Intel有深度合作,对于编码方面其实比我当时用RTX 3070还要更快,唯一的遗憾是Intel目前暂时没有更高端的显卡(A770的提升不大,所以不算),但是随着时间的推移,Intel的ARC独显也在不断发展,往后我们可能看完一部电影,而4K的高清修复就已经完成了,成本上可能不到1度电。
而这个成本和电影公司相比,犹如大海中的一颗芝麻,所以AI能火不是没有原因的。
从上面6个测试项目来看,相信大家也了解到CPU、NPU、GPU在AI中的定位和角色了。
总结
简而言之,CPU可以跑AI,但是效率太低,属于哼哧哼哧蛮力干活,但是不讨好;而GPU是AI中当之无愧的王者,即便是iGPU这样的集显也可以获得不错的加成,尤其是支持AI加速框架的iGPU或dGPU;而NPU的主要优势在于能效比,相比iGPU而言它的速度不慢,而能效方面仅需要30%~42%左右的iGPU功耗。
对于轻量级AI任务,我们完全可以使用NPU加速来完成,实现真正的多任务并行计算。

参考上述的走势图来看,这种效果得到了更好的印证,结合跑分对比,NPU的优势最大。
而对于重量级的AI任务,我们还是得借助dGPU独显来完成,根据不同的任务需求,比如编码方面我们选择A750这样的独显可以有效的降低成本,1500块钱就能搞定你要啥自行车是吧?

而且就OpenVINO加持下的A750同样可以获得RTX4060的效率:
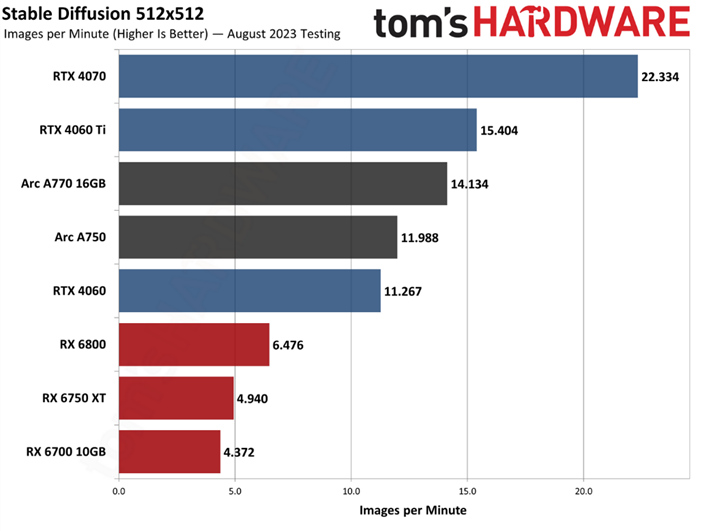
只有重量级的任务,并且要求速度特别快的时候,我们往往这时候才会考虑直接一步到位的RTX 4090独显。而日常中我们不管是使用A750还是RTX 4060或RTX 4070其实就够了。
注:上图中的数据是基于桌面级独立显卡的对比。
而日常生活中,AI对于我们来说更多的场景是帮我们把本地巨量的图片进行分类、标签化,比如搜图:
这些不仅在手机上得以体现,越来越多的NAS、私有云也在融入这样的功能,给我们的生活或者工作都带来了极大的效率,因为原来你要快速的找一张素材实在是太难了:
前期需要分门别类的整理,后期需要对图片加入标签化管理,人工成本太高,效果不是太理想。
但是有了AI加持,不管是用上面的Yolo v3算法,还是ResNet 50算法,都带来了很高的效率。
而在图像清晰化、超分辨率方面,即便是iGPU也能做到500毫秒一张图:
如果能支持NPU,1秒一张也不是不能接受,毕竟也就15瓦就可以搞定50瓦的事情,只能说太强了。
AI不限于AIGC文生图,AI还可以做很多事,尤其是重复而简单的事情,对人类来说过于枯燥、耗损时间,但是对于AI来说,它就算一个普通的指令,只是相对以往,它能实现更多的功能,帮我们做更多的事。
所以CPU肯定不是主角,它能做一部分的AI应用(即便没有AI加速引擎的加持下,本篇测试的CPU是有AI加速的哦),但是效率实在是太低了,属于是一件吃力不讨好的事情。而GPU才是真正的主角,在不同的条件下我们可以选择iGPU或者dGPU实现自己的需求;在日常的需求下我们还可以借助NPU这样的配角除了满足需求,还可以大大的降低能耗的开销,并且在集显的平台中,可以更好的实现多任务处理。
所以当下如果没有频繁的AIGC文生图需求,其实选择酷睿Ultra的轻薄本即可,比如它还有绘世这样的开源平台加持,可以玩出更多的花样(目前AMD平台暂时没有),如上的实测24秒生成20步迭代 512 x 512在需求不大的情况下是可以接受的(RTX 4060大概是4秒左右)。如果相对比较频繁,且一次要生成更多的样图来筛选,就轻薄而言可以选择设计本、全能本,有独显加持效果更好(因为并不是满载,所以效果和游戏本差异不大),一方面既解决了问题又解决了机动性轻薄的需求。
如果以此为生产力,肯定就需要真正的图形工作站平台了。
AI PC选型推荐
选型其实对于大家来说还是有壁垒和屏障的,因为有些东西光看是没用的,需要测。那么下面就主要基于集显轻薄本、全能本和迷你PC来推荐,游戏本主要是游戏诉求,一般参考游戏本的测评即可。AI对于游戏本来说属于顺带的事情,不用特别的太多考虑。
迷你PC
以大路用的华硕这款NUC来说,它的酷睿Ultra 5/7/9的Arc锐炫集显其实差异不大,所以就办公+小部分的AI需求来说,起步的酷睿Ultra 5 125H其实就可以完全胜任了:

选择U7或U9的版本更多是多核上加持更大,比如你有巨量的Excel等数据要处理,这种就无脑选择U9。

另外这三款里面还有一个区别,只有U9的版本电源适配器是150瓦的哦,细节可以参考测评:
搭配上因为是准系统,所以需要搭配DDR5-5600内存(最好是两条)和固态硬盘并安装系统就可以了。
其它类似联想、雷神也有类似的酷睿Ultra迷你PC,但是华硕这款性能释放是最强的。
轻薄集显本
轻薄的集显本一般是板载内存,并不能后续升级,就需求而言应该32GB起步和到头,16GB的版本不要去看,同样的集显不同的内存跑AI差异会比较大,板载高频的内存实际效果会比我上面的NUC会好一些,这个是高频内存的一些优势,而这样的机器一般也只有板载才有高频可选,支持扩展都是最大DDR5-5600,所以有的朋友说内存不能升级,其实并不是特别的缺陷,前提是你32GB起步。
这种机器联想的小新Pro 14我是测评过的,效果非常不错,价格推荐直接上U9版本:

测评可以参考:
另外能轻薄本里面能支持稳定的60瓦左右输出的其实并不太多,但是前面我们也看到了,一般用iGPU来跑,那么整机的功耗并不会太高,所以40瓦的输出也是可以选择的。
那么这时候类似于灵耀14其实就可以了:

同样惠普星Book Pro 14也是不错的选择:

全能本
全能本在这里主要是基于独立显卡的加持,所以并不用太介意一定是酷睿Ultra。
所以天选Air的AMD也是可以推荐的:

预算不高可选RTX 4050,7299就可以搞定,由于是独立显卡,所以板载内存的共享就不重要了:
顶配的测评参考:
荣耀今年也推出了自己的全能本,整机释放做到了140瓦,相对遥遥领先:

测评可以参考:
如何看待3月18日发布的荣耀旗舰笔记本MagicBook Pro 16,有哪些亮点和槽点?
如果预算能过万,且ROG的幻16 Air能更好的满足你的情绪价值,它是很不错的选择:

测评可以参考:
Views: 159